Sanskrit OCR Software Review
Oliver’s OCR tool is the best option for recognizing a Sanskrit text. It was so before 2010. It is even more so in 2013. I have heard Indian’s coders speaking (on Sanskrit conferences) long talks about how hard it is to make, and only this German guy made it possible. There are no real alternatives. Don’t even waste your time. Years ago Oliver’s software had a recognition rate 20-30% lower. It was free of charge at that time. It can be still downloaded (but no long from the official website). Starting from 2010 the updated version is sold and it’s accuracy rate is around 95%. Which is fantastic.
Indian books are printed on bad paper. There are enough ligatures than can make even a font designer go mad.

I have been working with Sanskrit OCRing for 11 years now. Until today — mostly romanized IAST. Indian quality printed IAST, good IAST — all kinds of them. I know how to make things run, train templates. Oliver’s Sanskrit OCR is where ABBYY FineReader was before v.7. It does the simple things and does them badly. It splits more frames than it should (instead of 2 columns it makes 7, but there never have been 7 column Sanskrit books). All OCR software has the same problems. Most of them get never solved. Not because they can not be. Because the wrong algorithm is used.

Major issues:
1) No batch recognize pages. I recognize one page at once. It takes a few days to recognize a 200 page book, just pressing same shortcut on every page. That’s insane. Never seen it even in the earliest versions of ABBYY Fine Reader.
Where is it? Batch export, I mean. And is there Batch analysis of the same layout for let’s say 1000 pages at once? Now I recognize each page at once. It takes around a minute for a page. So I have to keep the window open all the time and do monkey stuff.

2) No batch export recognized text. Maybe the batch export function is in HindiOCR (professional) for 199 Euros, but it is not there for SanskritOCR. So no batch option makes it very hard to use.
[Professional version only:] To store the text of all recognized pages in one file, use the option «All pages» in the list Batch export. Activate the option Store in separate pages if every recognized page should be stored in a separate file on disk.
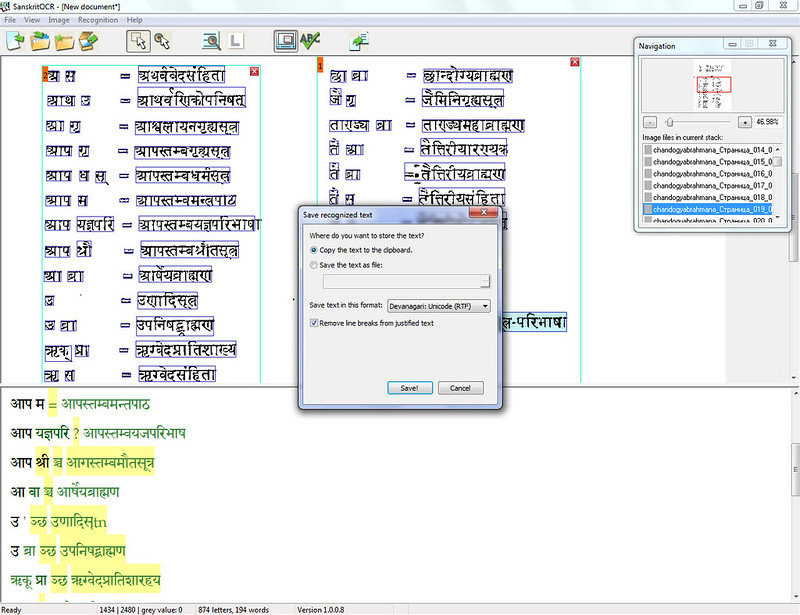
Smaller OCR Issues:
1) It looses dots in references all the time. It «clears» them as junk data, but when 2-4 Indian numbers come in a line, there is a good chance that after the 1st or 2nd a dot will come. And in most cases it is clear enough, but still gets killed.
Upper script numbers are not recognized as such.

2) There is no Save project option. Only when you close the tool it asks if you want to save. So you can loose all your work in a minute. Project is not as in ABBYY all the images and the OCR layer in one folder. It’s not even the OCR. It’s the master file, that I don’t know how is even connected. If I move the images to another disk, should I redo the OCR one page at a time?
3) When «Text recognition» mode starts the main windows closes and only a small one is visible. Does it has to be? When recognition ends, it opens again the main window.
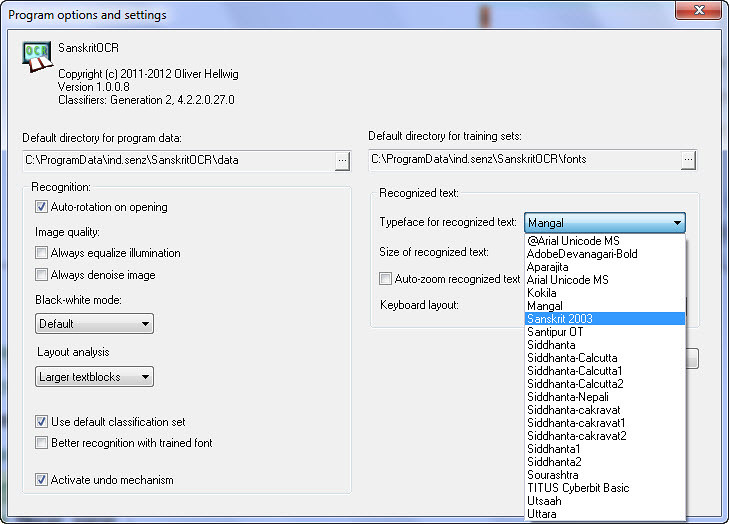
4) Options are rather too simplistic. And having Mangal instead of Sanskrit 2003 at least for Sanskrit ligatures is a bit… strange. Default font size 14 is rather small, 16 or 18 should be preferred.
5) The zoom for pages is not remembered. If I zoom 200%, when I click on next page it’s back to 10%. So there are next to no preferences. If I zoom in, the recognize Shorcut does not works anymore. So I have to go to the menu for every page. Too many clicks for a simple thing as this. And yes — the shortcut can’t be made with a single hand. Why not attach it to a single letter, like F5? Why on earth should I press 3 buttons?
See video http://www.youtube.com/watch?v=MjYNvHm_uyw
6) Let’s ignore Latin text. In scientific literature (and we worry about Sanskrit books, not Sanskrit newspapers) there happen to be footnotes. Many of which are in Latin letters. It would be a huge progress if after encountering a lot of «bad» Devanagari it would stop making nonsense OCR at all. If it manages 800 ligatures, it can manage 30 Latin letters, right? At least to kill ’em.
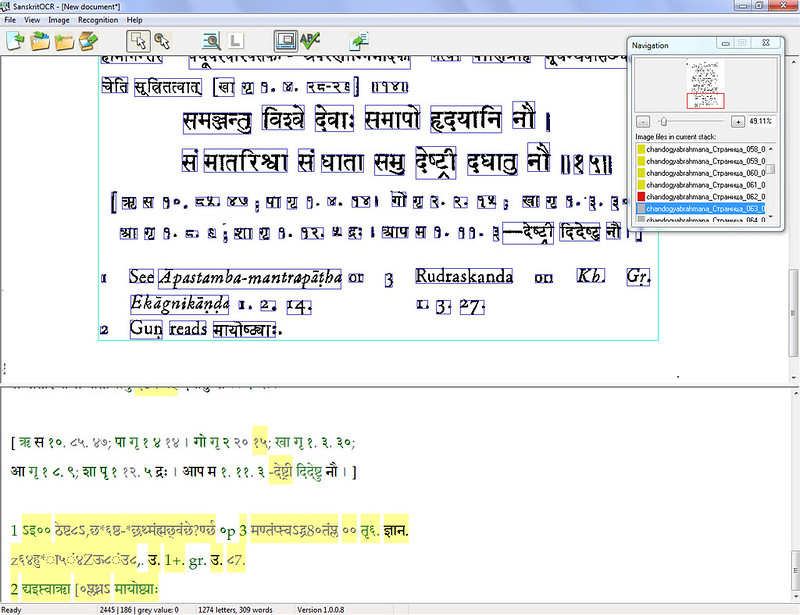
7) Initial importing of images can take a few hours. It does not matters much, but for a 1020 page dictionary one must be patient. Speed is not too high and I don’t mean the recognition, it’s just the loading of .jpgs. Importing .pdf option would be nice as well. Because exporting .jpg from a .pdf means pixels lost and worse OCR results.
8) The icons, UI is like built in 1999. If Oliver would agree I could draw for free icons same style as http://www.fatcow.com/free-icons just to make it look like it’s not ’99.
![]()
9) If you don’t mark a text block before starting recognition, the program automatically uses layout analysis to detect the text blocks.
Should it mean, if I draw the layout and don’t touch anything it will be applied to all pages?
It is the best tool out there. The others are much worse, I’ve scanned thousand of books. I’ve OCRed hundred of them. Believe me. But without batch features it does not makes much sense even for the best Sanskrit OCR tool.

On DSC website we see, that it’s possible to add a «dirty» OCR layer of devanagari to book scans. To see it not online, but offline and in .pdf books would be a revolution. But we are not yet ready for it. And there is not a strong enough demand. Searching devanagari in .pdf is still a pain, even with a «clean» Unicode text.